11 minutes
Exploring Ruby Ractors
Ruby Ractors Adventure
“I paid for 10 cores, I’m gonna use 10 cores!”
I set out today for a silly explore hoping to waste some CPU with a whole bunch of ractors doing math, but I find that YJIT is pretty amazing.
Ruby 3.0.0 came out in December 2020, more than 4 years ago now, and with it came Ractors (and Fiber Scheduler but that’s another episode). Ractors promised a way to run truly concurrent things within the same ruby process. Ruby has a problem with lots of things being shared and the GVL essentially protects those shared accesses. With ractors, you can run code that is only allowed to share with other ractors in very specific ways. This allows multiple ractors to run code concurrently, as though there were multiple, per-ractor, GVLs.
I found myself with some time to spare and wanted to see where Ractors stood in the most recent stable ruby version, 3.4.2. Here’s what I discovered.
The Promise
The GVL is dead! With Ractors we can now run ruby code with true concurrent parallelism!
Awesome! Kinda!
Most of the time ruby applications, especially things like web services, rails apps, etc are not CPU bound, at least not in a way where ractors really help. A lot of smarter people than I have written about why it turns out in practice there are better ways to take advantage of all the lightning trapped in the sand in your computer.
However, it has long been the story that ruby “can’t do true concurrency due to the GVL”, and in fact that was my own experience most of my career. I just want to run some ruby code at 1000% CPU! Lets do it!
Starting with some Benchmarks
These tests have all been run with ruby 3.4.2, the latest stable at time of writing.
CPU Bound Benchmark
Since Ractors should finally let us run pure-ruby code at MAXIMUM CONCURRENCY, thats where I wanted to start. In my understanding, and based on the ruby 3.0 release notes1, I figured I could take some trivial CPU work, throw it in parallel ractors, and joyfully witness my ruby process use more than 100% CPU burning through the work. Of course, the work should be done truly concurrently and we should see a noticeable (scaling with number of ractors) reduction in total execution time too!
Simulate CPU Bound Work
After reading “What’s The Deal With Ractors?” by Byroot and “An Introduction to Ractors in Ruby” by Abiodun Olowode, I quickly had some code I should be able to run at 1000% CPU.
Fibonacci
# This is a naive recursive Fibonacci implementation.
# Pretty slow for anything > 35
def fibonacci(n)
((n == 0 || n == 1) && n) || fibonacci(n - 1) + fibonacci(n - 2)
end
Tarai
See Ruby 3.0.0 Release Notes1 that also used this code as an example of Ractor benefits.
def tarai(x, y, z) =
x <= y ? y : tarai(tarai(x-1, y, z),
tarai(y-1, z, x),
tarai(z-1, x, y))
Compare Ractors to Baseline
Largely inspired by Byroot’s example, I threw together these two benchmark files that could be run with a simple ruby fibo.rb or ruby tarai.rb.
require 'benchmark'
CONCURRENCY = 10
STARTING_PARAMS = [14, 7, 0].freeze
def tarai(x, y, z) =
x <= y ? y : tarai(tarai(x-1, y, z),
tarai(y-1, z, x),
tarai(z-1, x, y))
# Calls tarai n times serially.
# Used as a baseline for comparison.
def serial_tarai(n)
n.times.map { tarai(*STARTING_PARAMS) }
end
def threaded_tarai(n)
n.times.map do
Thread.new { tarai(*STARTING_PARAMS) }
end.map(&:value)
end
def ractor_tarai(n)
n.times.map do
Ractor.new { tarai(*STARTING_PARAMS) }
end.map(&:take)
end
#start_benchmark
Benchmark.bm(15, ">times faster:") do |x|
s = x.report('serial') { serial_tarai(CONCURRENCY) }
t = x.report('threaded') { threaded_tarai(CONCURRENCY) }
r = x.report('ractors') { ractor_tarai(CONCURRENCY) }
[t/r]
end
#end_benchmark
require 'benchmark'
CONCURRENCY = 10
FIB_NUM = 38
# This is a naive recursive Fibonacci implementation.
# Pretty slow for anything > 35
def fibonacci(n)
((n == 0 || n == 1) && n) || fibonacci(n - 1) + fibonacci(n - 2)
end
# Calls fibonacci n times serially.
# Used as a baseline for comparison.
def serial_fibonacci(concurrency, n)
concurrency.times.map do
fibonacci(n)
end
end
def threaded_fibonacci(concurrency, n)
concurrency.times.map do
Thread.new { fibonacci(n) }
end.map(&:value)
end
def ractor_fibonacci(concurrency, n)
concurrency.times.map do
Ractor.new(n) { |num| fibonacci(num) }
end.map(&:take)
end
#start_benchmark
Benchmark.bm(15, ">times faster:") do |x|
s = x.report('serial') { serial_fibonacci(CONCURRENCY, FIB_NUM) }
t = x.report('threaded') { threaded_fibonacci(CONCURRENCY, FIB_NUM) }
r = x.report('ractors') { ractor_fibonacci(CONCURRENCY, FIB_NUM) }
[t/r]
end
#end_benchmark
You can find this code, and some other benchmarks in my ruby-ractor-benchmarks repository.
Getting Some Results
[!NOTE] Benchmark Consistency is Hard! Early in this process I got highly variable results from my benchmarks. I identified issues with my local ruby install that were causing unreliable results. I am still not 100% convinced that my docker case is correct. However, the results I’ve now reached are highly reproducible. They produce reliable results on every machine I try. After iteratively isolating and removing issues, I’ve reached a point where my test cases are reproducing results within error bars that are good enough for me.
Some Success
We did it! We got a lot more than 100% CPU from one ruby process.

Nice.
Bad Results at First
However, initially I got some very disappointing results on my M1 Macbook Pro. Ractors were consuming CPU in parallel, but the end result was no faster than serial, and sometimes quite a bit worse, with ractors sometimes real time taking longer than serially.
eg for 4 & 8 concurrency I was getting these results:
ruby 3.4.2 (2025-02-15 revision d2930f8e7a) +PRISM [arm64-darwin24]
Benchmarking 4 Iterations
tak.rb:17: warning: Ractor is experimental, and the behavior may change in future versions of Ruby! Also there are many implementation issues.
user system total real
serial 55.316336 0.168104 55.484440 ( 55.549630)
ractors 156.600156 0.191462 156.791618 ( 39.417857)
Benchmarking 8 Interations
user system total real
serial 112.069091 0.457459 112.526550 (113.354157)
ractors 517.257652 1.860301 519.117953 ( 87.999958)
113s vs 88s! Something didn’t seem right. I expected to see multiple X faster, especially when running 8 ractors, but I was only seeing 1.3x faster here.
[!TIP] Sometimes it’s a weird thing In the process of debugging very bad results on my machine, I started eliminating variables. I reinstalled ruby 3.4.2 and saw much better results that were much more consistent with posts online and reasonable expectations. I haven’t had unexplainably poor results on macOS since. It must be that my ruby 3.4.2 that had been installed was somehow subtly broken. It worked correctly, but was much slower than a fresh install is.
Finally I was seeing nice results on my M1. Ractors were faster by 3.98x when running with 4 ractors. That seems exactly right.
user system total real
serial 39.366752 0.185297 39.552049 ( 40.075137)
threaded 39.115326 0.231115 39.346441 ( 39.840468)
ractors 58.220778 0.133225 58.354003 ( 10.010694)
>times faster: 0.671845 1.734772 NaN ( 3.979791)
Perplexing Docker Results
One interesting thing I seem to be able to reproduce is ractors being slower AND much less efficient in docker on my MacBook as well as a AMD box.
For example, our fibonacci benchmarks/fibo_bm.rb when run in docker on ruby 3.4.2 (2025-02-15 revision d2930f8e7a) +PRISM [aarch64-linux].
user system total real
threaded 41.955226 0.009052 41.964278 ( 41.917704)
ractors 330.931238 0.020016 330.951254 ( 55.260660)
>times faster: 0.126779 0.452238 NaN ( 0.758545)
The ractors total time here is 55s compared to threaded performance of 41s! What’s worse, we see that Ractors did use plenty of concurrent CPU time.
And our benchmarks/tarai_bm.rb example also does poorly in docker
user system total real
threaded 112.883811 0.048076 112.931887 (112.804605)
ractors 1021.533082 0.047153 1021.580235 (170.324781)
>times faster: 0.110504 1.019575 NaN ( 0.662291)
I would love to know why this is. I first checked docker to see if my local macOS results were reasonable. These results supported my theory.
In docker, I get similar results, where ractors are slower than serial, on x86_64 CPUs as well.
/usr/local/bin/ruby benchmarks/fibo_bm.rb
Initializing Fibonacci benchmark from benchmarks/fibo_bm.rb...
Ruby Information:
{RUBY_DESCRIPTION: "ruby 3.4.2 (2025-02-15 revision d2930f8e7a) +PRISM [x86_64-linux]", YJIT_enabled: false}
Running Fibonacci benchmark from benchmarks/fibo_bm.rb @ 2025-03-20 07:48:49 +0000...
user system total real
threaded 42.572746 0.015913 42.588659 ( 42.509952)
ractors 204.814097 0.000000 204.814097 ( 52.661219)
>times faster: 0.207860 Inf NaN ( 0.807234)
Finished Fibonacci benchmark from benchmarks/fibo_bm.rb @ 2025-03-20 07:50:24 +0000.
Elapsed time: 95.17 seconds.
-------------------------
More to Discover Here
I don’t know why these docker results are so poor, but I’d like to know more. It seems worth looking into why ractors are slower in this case. Perhaps using a tool like vernier could provide some more insights.
I’m still investigating the surprising Docker performance issues and plan to explore this further in a follow-up post. If you have insights about Ractor performance in containerized environments, or other cases where ractors are shown to be worse than serial, I’d love to hear your thoughts!
Shout out to Vernier
https://vernier.prof/ I follow John Hawthorn on bluesky and heard about vernier there from him. Out of interest I ran the good examples in vernier and the output was very cool.
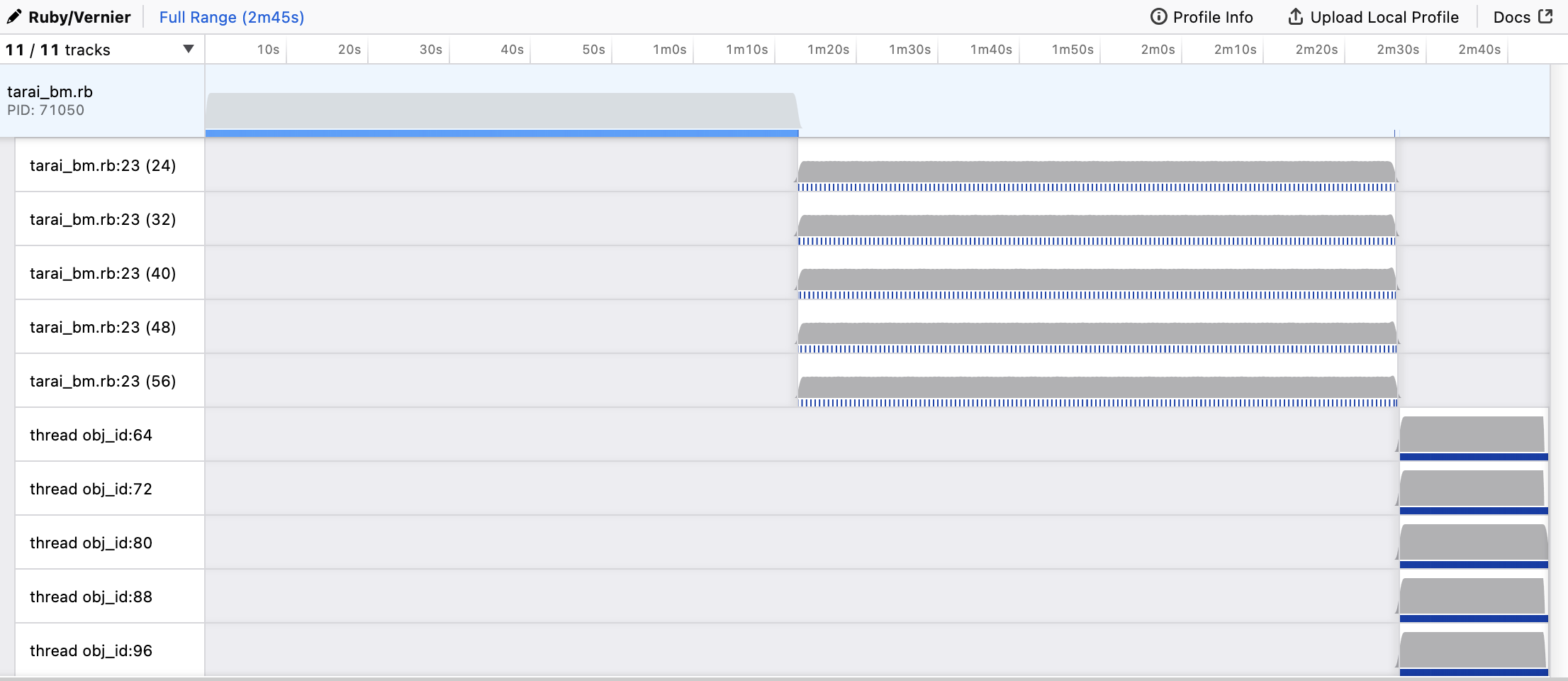
Here you can see the three approaches, serial, threaded, and ractored.
In the serial case you see the single thread doing the complete set of work, in the threaded, you see 5 threads, but if you look at the blue blocks you can see that only one of these threads is executing at a time, also note that the total time is basically the same as the serial approach. In the ractor approach, you see two notable things: 5 solid blue lines in the threads, all 5 threads were executing the entire time, and the total time was much shorter!
Another thing vernier makes clear is that our entire execution is in recursion. The code also makes that clear when you think about it, but with vernier it starts to tell a story. The flame graphs and stack charts are just stacks and blocks of our own method calling itself. There’s nothing that algorithmically hard about the code we’ve written. All that time we’re spending is in interpreting and calling very simple ruby code quite recursively.
The Real Star – YJIT
Somewhere along this journey, perhaps while reading Byroot’s blog post, perhaps while feeling quite underwhelmed by the speed the benchmarks were running, I wondered how YJIT could help here.
YJIT is “Yet Another Ruby JIT” , that seems to be getting significantly better with each release. Simplified, when YJIT is enabled, ruby code is compiled “just in time” into more efficient machine code for faster execution.
It so happened that my ruby was already compiled with yjit support so all I had to do was run ruby with --yjit and my benchmarks would run with yjit.
I was honestly floored. My fibonacci output went from this:
user system total real
serial 39.231936 0.283801 39.515737 ( 39.969249)
threaded 39.144448 0.211080 39.355528 ( 39.769842)
ractors 58.340113 0.209830 58.549943 ( 10.050438)
>times faster: 0.670970 1.005957 NaN ( 3.957026)
Finished Fibonacci benchmark from benchmarks/fibo_bm.rb @ 2025-03-20 01:00:20 -0700.
Elapsed time: 89.84 seconds.
to this:
user system total real
serial 3.708983 0.023323 3.732306 ( 3.785196)
threaded 3.710992 0.025232 3.736224 ( 3.781451)
ractors 4.506470 0.019225 4.525695 ( 0.775657)
>times faster: 0.823481 1.312458 NaN ( 4.875159)
Finished Fibonacci benchmark from benchmarks/fibo_bm.rb @ 2025-03-20 01:00:28 -0700.
Elapsed time: 8.34 seconds.
Whoa! That’s incredible. Ractors was a chance to use 4x the cores for 4x the performance, but yjit has given us a 10-13x speedup for free! 10x in the serial case, and 13x in the ractor case!
YJIT has been production ready since 3.2. https://shopify.engineering/ruby-yjit-is-production-ready but it seems it has only gotten better since then.
Shopify/yjit-bench has much more comprehensive yjit benchmarking than I will ever attempt.
Other Effects on Results
YJIT also improves the docker case significantly, but doesn’t remedy it entirely, at least not on x86.
Conclusions
- My benchmark repo is available at jpterry/ruby-ractor-benchmarks.
- Honestly, Ractors are NOT production ready. There is a warning that I’ve suppressed in all my benchmarks. “There are many implementation issues.”
- If you’re looking for speedups, use YJIT, it’s production ready and will have wide ranging impact, probably for free.
- Ractors give us more GVLs to burn more CPUs and I think thats neat.
- Really tho, things like async, and probably pitchfork are better fit solutions to most of ruby’s current needs in the wild
Notes
-
In the examples and results above I am sometimes using 10 concurrency, but most times using 4, and only once using 8. 4 was a useful number to prove wins, seemed realistic, and was a number I could more easily test in multiple architectures (I have other computers with 4 cores). 10 was an attempt to show lots of CPU usage in activity monitor.
-
ruby 3.4.2 (2025-02-15 revision d2930f8e7a)was used in all tests:- Natively on M1 macOS
- In docker linux on M1
- In docker linux on AMD
Thanks to:
- Byroot (Jean Boussier) & Appsignal (Abiodun Olowode)
- Other folks writing blog posts I’ve read
Referenced Posts
- “What’s The Deal With Ractors?” - Byroot (Jean Boussier)
- “An Introduction to Ractors in Ruby” - AppSignal Blog - Abiodun Olowode
- My
ruby-ractors-benchmarksrepository.
Footnotes
-
The ruby 3.0.0. release notes is the first to mention tarai as a Ractor benchmark, including a link to their source, wikipedia article Tak (function). ↩︎ ↩︎